CompCap: Improving Multimodal Large Language Models with Composite Captions








 Shen Yan
Xuewen Zhang
Shen Yan
Xuewen Zhang

Abstract
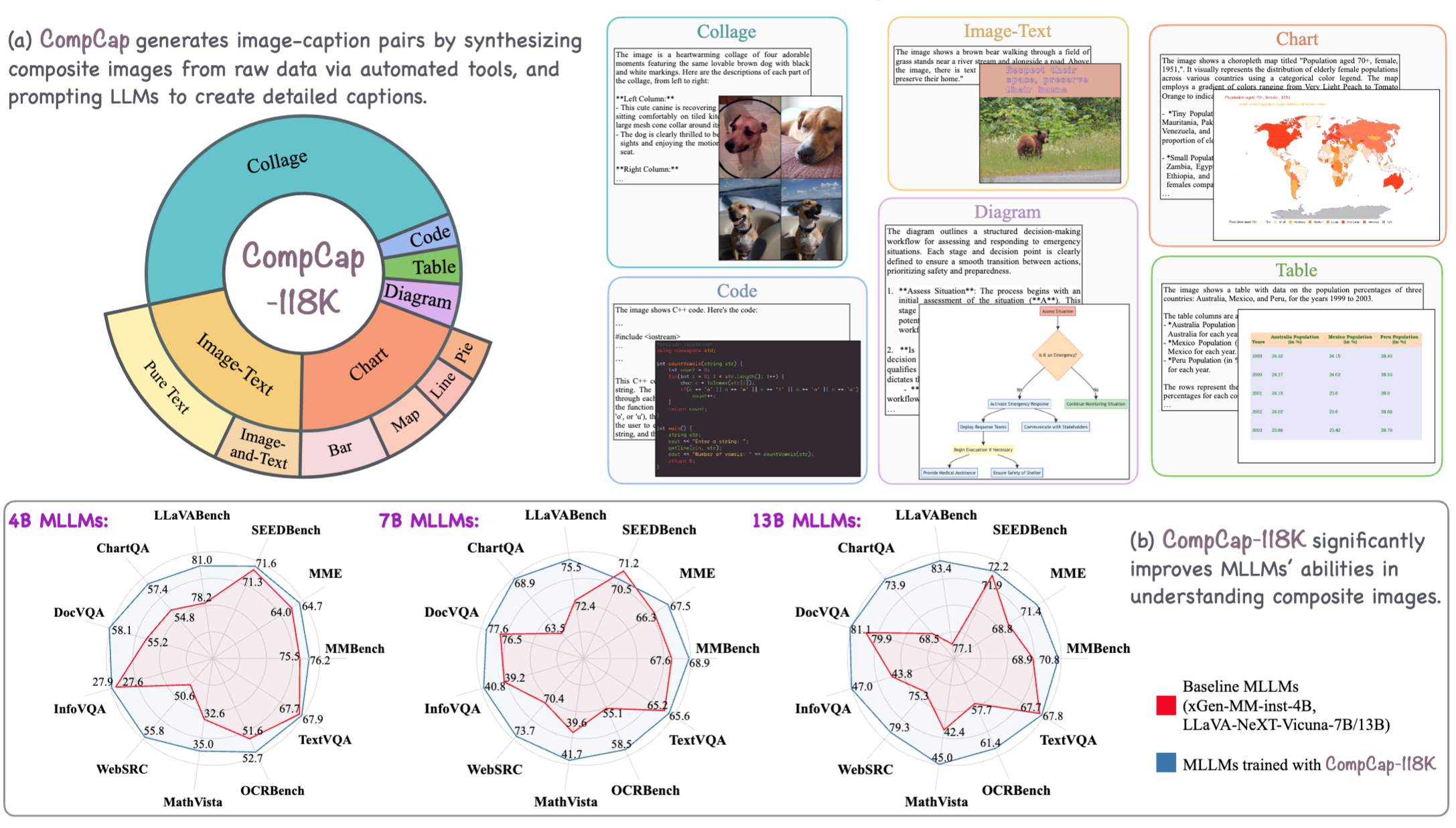
How well can Multimodal Large Language Models (MLLMs) understand composite images? Composite images (CIs) are synthetic visuals created by merging multiple visual elements, such as charts, posters, or screenshots, rather than being captured directly by a camera. While CIs are prevalent in real-world applications, recent MLLM developments have primarily focused on interpreting natural images (NIs). Our research reveals that current MLLMs face significant challenges in accurately understanding CIs, often struggling to extract information or perform complex reasoning based on these images. We find that existing training data for CIs are mostly formatted for question-answer tasks (e.g., in datasets like ChartQA and ScienceQA), while high-quality image-caption datasets, critical for robust vision-language alignment, are only available for NIs. To bridge this gap, we introduce Composite Captions (CompCap), a flexible framework that leverages Large Language Models (LLMs) and automation tools to synthesize CIs with accurate and detailed captions. Using CompCap, we curate CompCap-118K, a dataset containing 118K image-caption pairs across six CI types. We validate the effectiveness of CompCap-118K by supervised fine-tuning MLLMs of three sizes: xGen-MM-inst.-4B and LLaVA-NeXT-Vicuna-7B/13B. Empirical results show that CompCap-118K significantly enhances MLLMs’ understanding of CIs, yielding average gains of 1.7%, 2.0%, and 2.9% across eleven benchmarks, respectively.
BibTeX
@article{chen2024compcap,
title={Compcap: Improving multimodal large language models with composite captions},
author={Chen, Xiaohui and Shukla, Satya Narayan and Azab, Mahmoud and Singh, Aashu and Wang, Qifan and Yang, David and Peng, ShengYun and Yu, Hanchao and Yan, Shen and Zhang, Xuewen and others},
journal={arXiv preprint arXiv:2412.05243},
year={2024}
}