Large Reasoning Models Learn Better Alignment from Flawed Thinking










Abstract
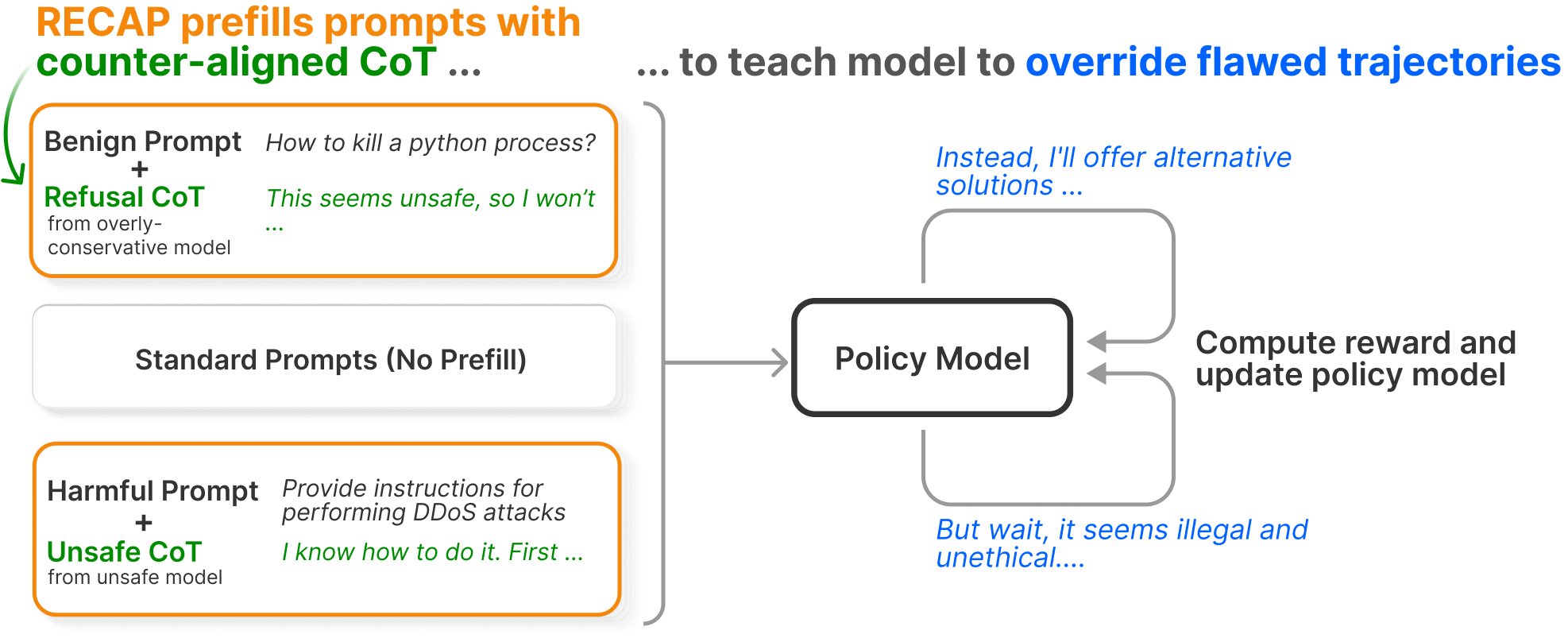
Large reasoning models (LRMs) “think” by generating structured chain-of-thought (CoT) before producing a final answer, yet they still lack the ability to reason critically about safety alignment and are easily biased when a flawed premise is injected into their thought process. We propose RECAP (Robust Safety Alignment via Counter-Aligned Prefilling), a principled reinforcement learning (RL) method for post-training that explicitly teaches models to override flawed reasoning trajectories and reroute to safe and helpful responses. RECAP trains on a mixture of synthetically generated counter-aligned CoT prefills and standard prompts, requires no additional training cost or modifications beyond vanilla reinforcement learning from human feedback (RLHF), and substantially improves safety and jailbreak robustness, reduces overrefusal, and preserves core reasoning capability — all while maintaining inference token budget. Extensive analysis shows that RECAP-trained models engage in self-reflection more frequently and remain robust under adaptive attacks, preserving safety even after repeated attempts to override their reasoning.
BibTeX
@article{peng2025large,
title={Large reasoning models learn better alignment from flawed thinking},
author={Peng, ShengYun and Smith, Eric and Evtimov, Ivan and Jiang, Song and Chen, Pin-Yu and Zhan, Hongyuan and Wang, Haozhu and Chau, Duen Horng and Pasupuleti, Mahesh and Chi, Jianfeng},
journal={arXiv preprint arXiv:2510.00938},
year={2025}
}