Diffusion Explainer: Visual Explanation for Text-to-image Stable Diffusion








 Haoyang Yang
Haoyang Yang

Abstract
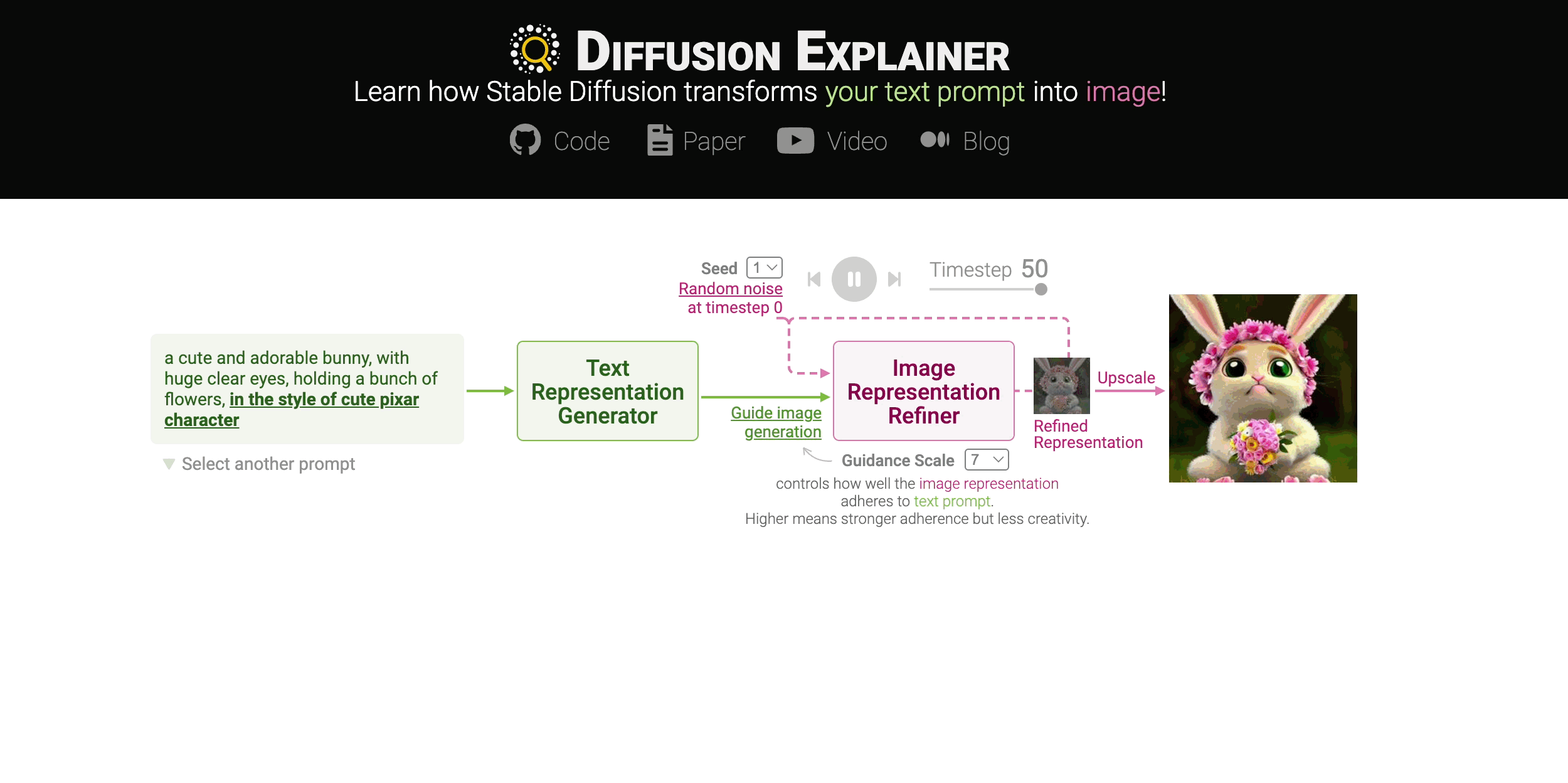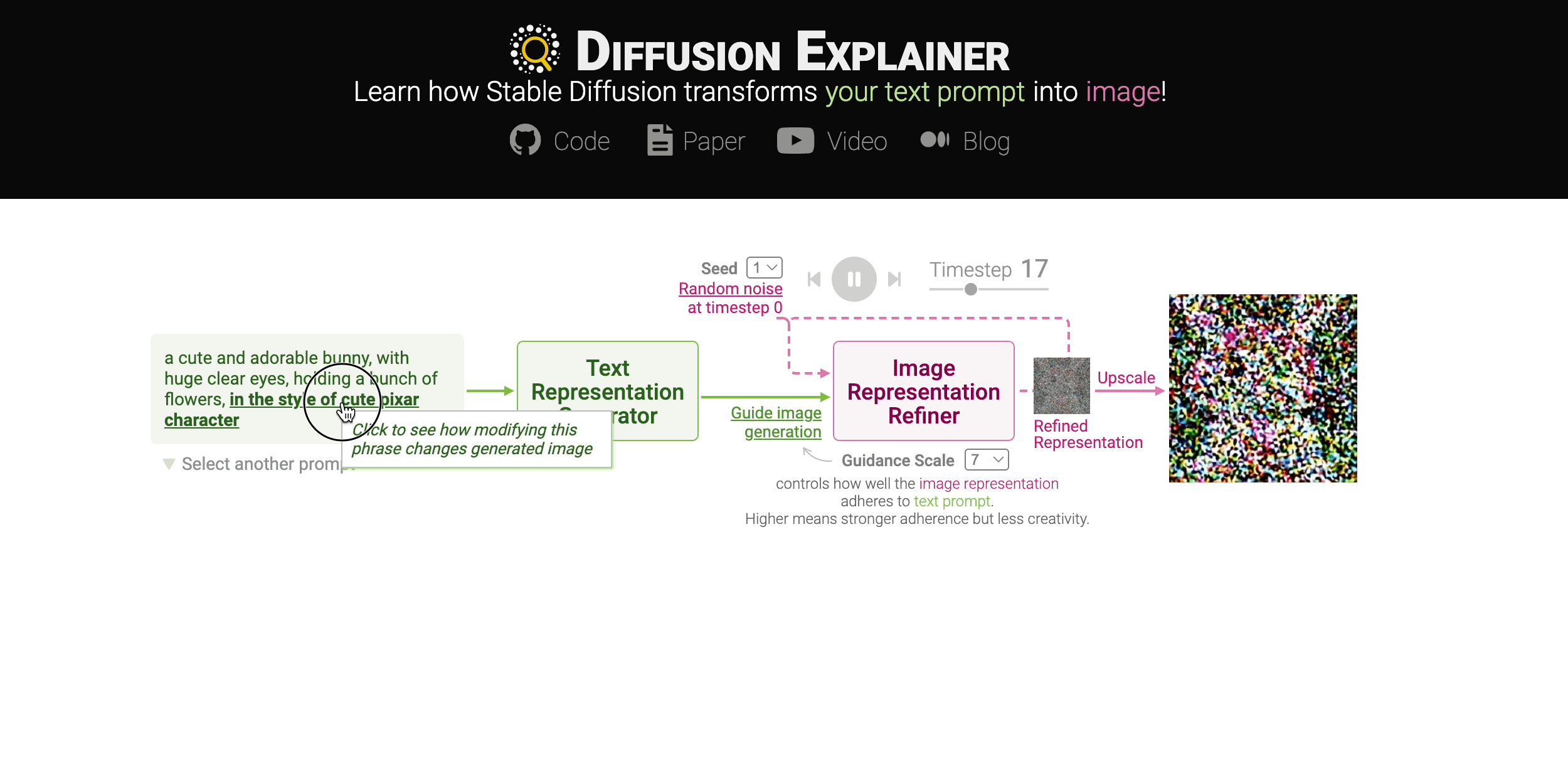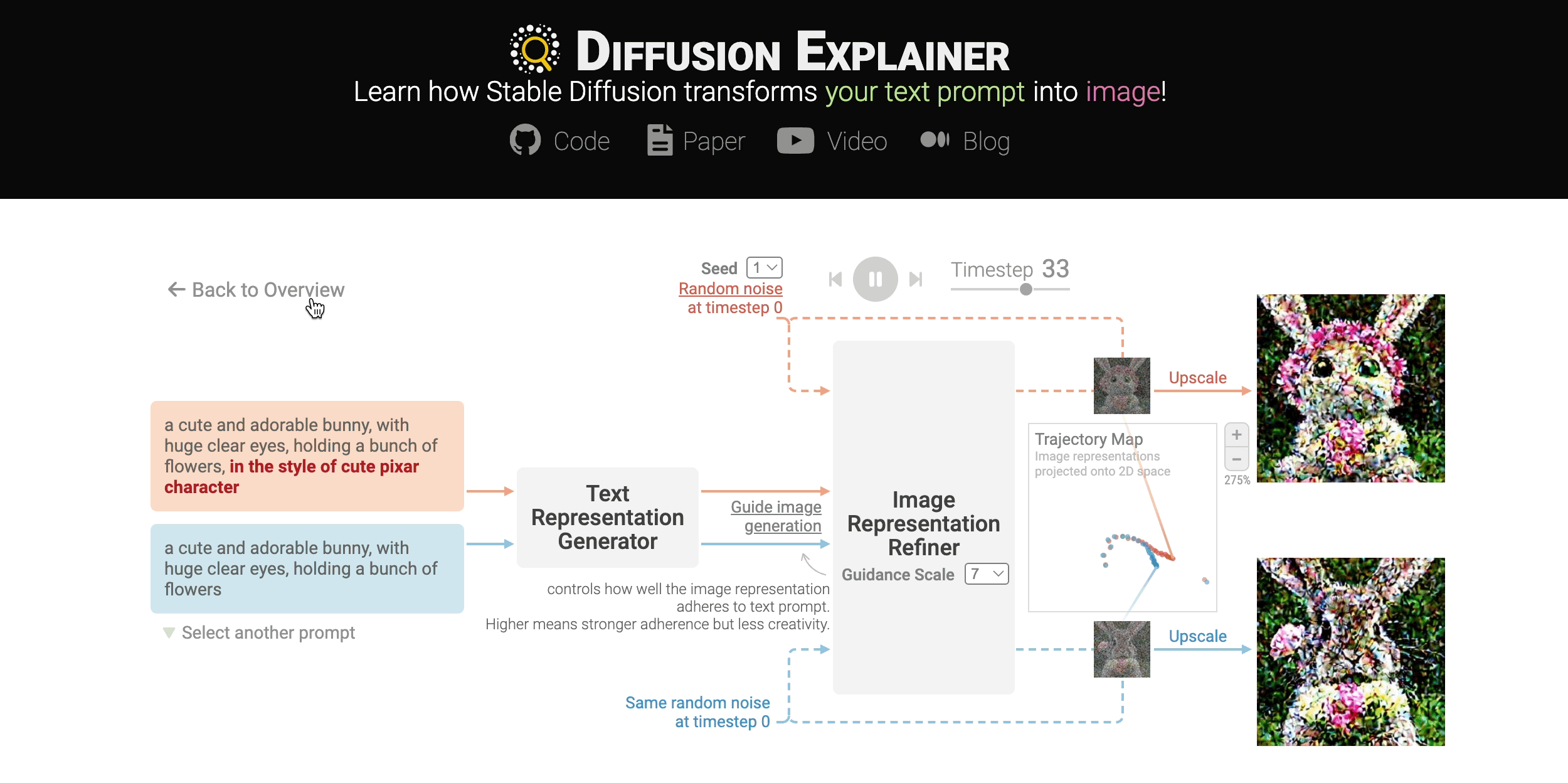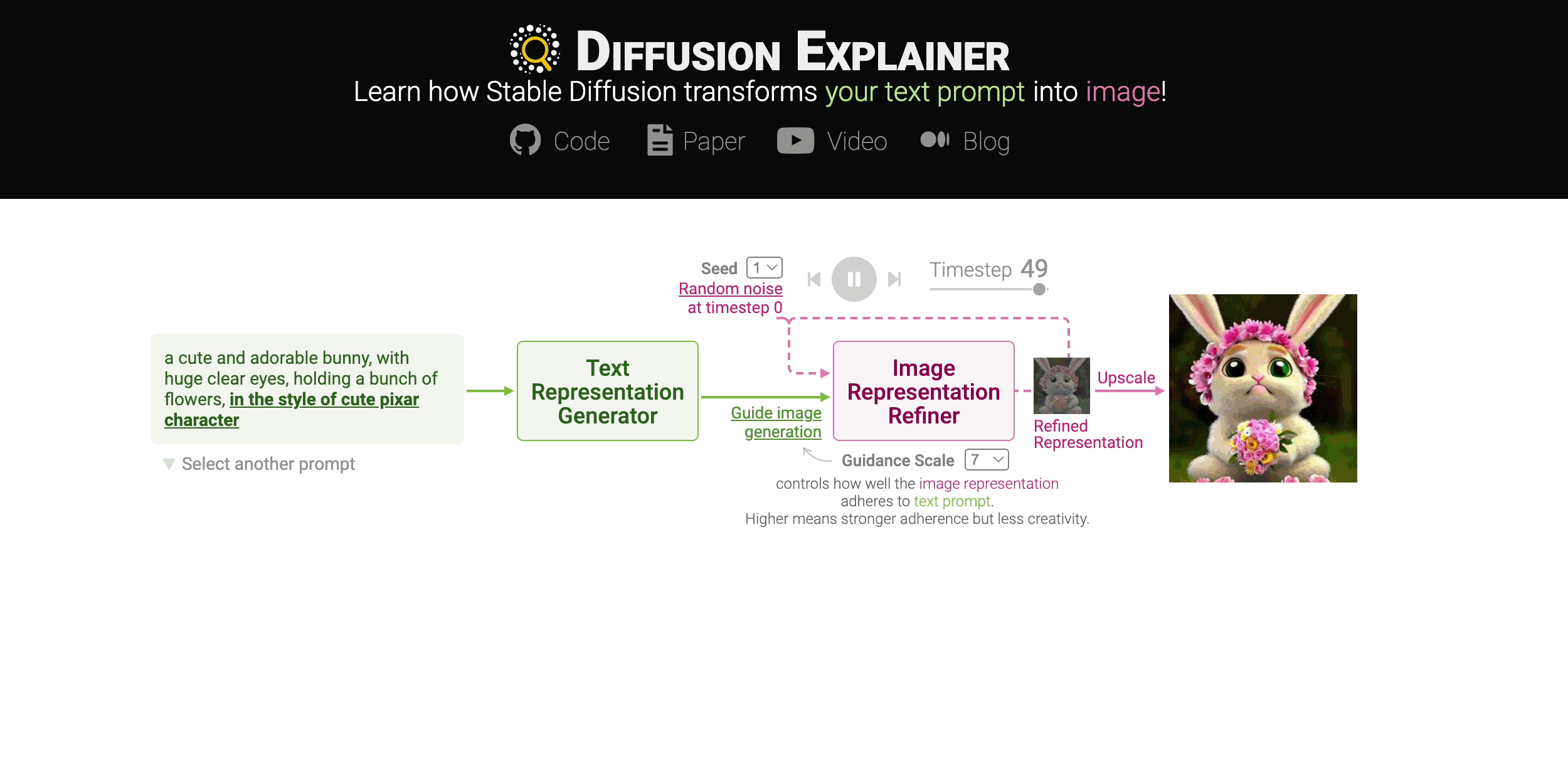
Diffusion-based generative models’ impressive ability to create convincing images has captured global attention. However, their complex internal structures and operations often make them difficult for non-experts to understand. We present Diffusion Explainer, the first interactive visualization tool that explains how Stable Diffusion transforms text prompts into images. Diffusion Explainer tightly integrates a visual overview of Stable Diffusion’s complex components with detailed explanations of their underlying operations, enabling users to fluidly transition between multiple levels of abstraction through animations and interactive elements. By comparing the evolutions of image representations guided by two related text prompts over refinement timesteps, users can discover the impact of prompts on image generation. Diffusion Explainer runs locally in users’ web browsers without the need for installation or specialized hardware, broadening the public’s education access to modern AI techniques.
BibTeX
@article{lee2023diffusion,
title={Diffusion Explainer: Visual Explanation for Text-to-image Stable Diffusion},
author={Lee, Seongmin and Hoover, Benjamin and Strobelt, Hendrik and Wang, Zijie J and Peng, ShengYun and Wright, Austin and Li, Kevin and Park, Haekyu and Yang, Haoyang and Chau, Duen Horng},
journal={arXiv preprint arXiv:2305.03509},
year={2023}
}