Inference Compute-Optimal Video Vision Language Models


 Xuewen Zhang
Xuewen Zhang



Abstract
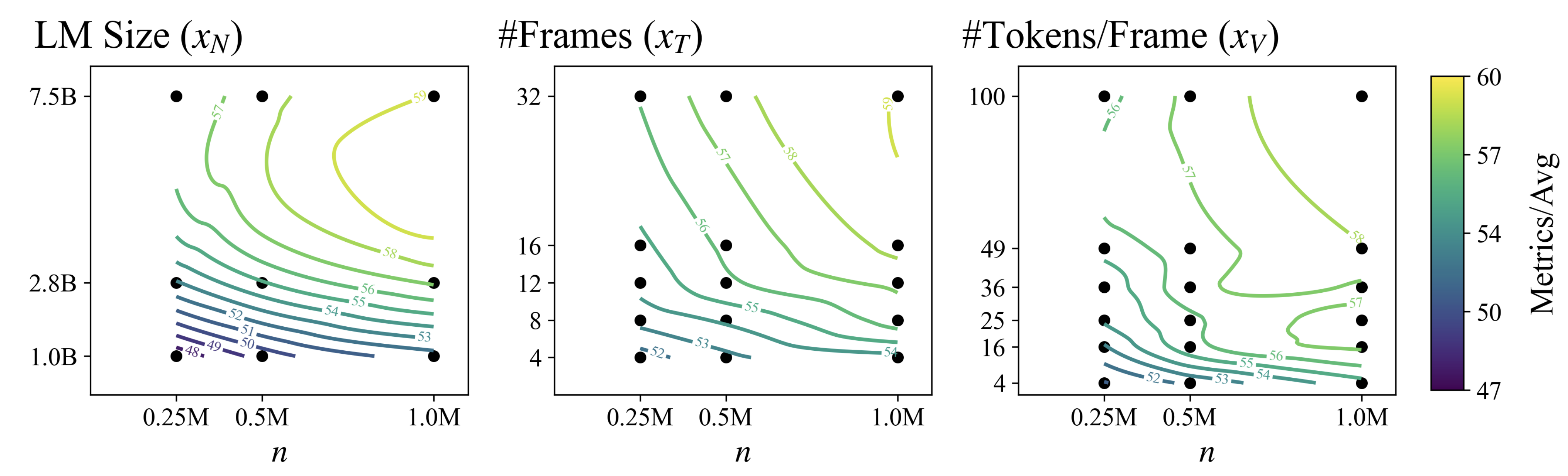
Video Vision Language Models (VLMs) have achieved remarkable performance across a wide range of video tasks. While significant efforts have been made to enhance model performance, limited attention has been given to identifying the optimal model architecture under a fixed inference compute budget. This study explores how to best allocate inference compute across three critical scaling factors in video VLMs: language model size, frame count, and the number of visual tokens per frame. Through extensive large-scale training sweeps and careful parametric modeling of task performance, we identify the inference compute-optimal frontier. Our experimental results illuminate the relationship between task performance and scaling factors, as well as the impact of finetuning data size on this efficiency frontier. These insights provide practical guidance for selecting the optimal scaling factors in video vision language models.
BibTeX
@article{wang2025inference,
title={Inference Compute-Optimal Video Vision Language Models},
author={Peiqi Wang, ShengYun Peng, Xuewen Zhang, Hanchao Yu, Yibo Yang, Lifu Huang, Fujun Liu, Qifan Wang},
journal={ACL},
year={2025}
}